A Generative Adversarial Network (GAN) is a powerful method for generating samples from an unknown distribution, particularly hard to model distributions such as images. In this post we will shortly introduce the GAN model, and then focus on two major failure modes of these models, namely Vanishing Gradient and Mode Collapse. We will conclude by briefly mentioning the state of the art methods in GAN literature. Note that this post is mainly focused on certain theoretical analysis of the failure modes of GANs, for details of algorithms and their respective guarantees see the referenced papers.
1. Definitions
We start by looking at the task definition and the way GANs try to model the task.
1.1. Problem Statement
Let  be the real data distribution and
be the real data distribution and  be the model distribution parametrized by
be the model distribution parametrized by  . Given m samples from
. Given m samples from 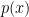 the task is to estimate
the task is to estimate  “close” to . We may refer to
“close” to . We may refer to 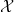 as image space in the remainder of this post, however it can be any data distribution. Notice that there are many ways to model this task, for example the kernel density estimation methods model
as image space in the remainder of this post, however it can be any data distribution. Notice that there are many ways to model this task, for example the kernel density estimation methods model  by windows passing over the given samples. Next we will look at the adversarial modeling of this task by [Goodfellow et al. 2014].
by windows passing over the given samples. Next we will look at the adversarial modeling of this task by [Goodfellow et al. 2014].
1.2. GAN Model
Consider the following continuous differentiable functions (e.g. defined by Neural Nets):
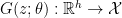
![\displaystyle D(x;w): {\cal X} \rightarrow [0, 1]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++D%28x%3Bw%29%3A+%7B%5Ccal+X%7D+%5Crightarrow+%5B0%2C+1%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
We refer to  as the “generator” and is the model distribution induced by sampling from this function using
as the “generator” and is the model distribution induced by sampling from this function using  . We refer to
. We refer to  as the “discriminator” and it is essentially a binary classifier (before thresholding). We might drop the parameters and
as the “discriminator” and it is essentially a binary classifier (before thresholding). We might drop the parameters and  for brevity in some equations. We further assume that and are universal approximators.
for brevity in some equations. We further assume that and are universal approximators.
The idea is to train towards perfectly discriminating real samples 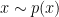 from fake samples
from fake samples 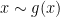 , and in turn train towards confusing , hence the term “Adversarial Networks”, and in doing so we conjecture that would end up generating samples “close” to the real data distribution. More concretely we define a loss as follows:
, and in turn train towards confusing , hence the term “Adversarial Networks”, and in doing so we conjecture that would end up generating samples “close” to the real data distribution. More concretely we define a loss as follows:

Or equivalently:
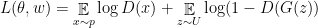
And then the training process is:
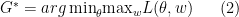
Note that we use 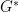 and
and 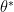 interchangeably to refer to optimal generator, similarly for discriminator. This optimization is formulated to capture the mentioned adversarial intuition, however this is of course not the only way to model the intuition, a point to which we’ll return at the end of this blog post.
interchangeably to refer to optimal generator, similarly for discriminator. This optimization is formulated to capture the mentioned adversarial intuition, however this is of course not the only way to model the intuition, a point to which we’ll return at the end of this blog post.
2. Theorems and Analysis
In this section we first provide a theoretical validation for the GAN model, and then provide theorems and analysis regarding the failure modes of GANs.
2.1. GAN Convergence
The optimization defined in Equation (2) intuitively brings close to , however we need a more concrete guarantee that this in fact happens. The following theorem by [Goodfellow et al. 2014] shows that at the optimum, the solution to Equation (2) is 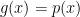 .
.
Theorem 1 The result of  is
is  .
.
Proof: We first rewrite  in its integral form:
in its integral form:
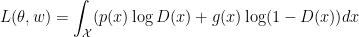
Now at each  , we find
, we find 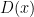 that maximizes the term inside the integral, by taking the derivative wrt :
that maximizes the term inside the integral, by taking the derivative wrt :

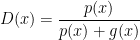
Thus we have:

Now we replace this  into the definition of
into the definition of  :
:
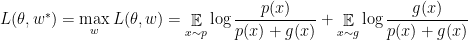
Given the definition of Kullback Leibler Divergence  we have:
we have:

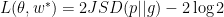
where 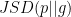 is the Jensen Shannon Divergence and is replaced by definition. It is known that
is the Jensen Shannon Divergence and is replaced by definition. It is known that  , and the lower bound equality only happens when
, and the lower bound equality only happens when  . Thus the result of
. Thus the result of  is
is  over .
over . 
2.2. Vanishing Gradient
Before we provide a theorem describing the Vanishing Gradient issue, we need to consider some assumptions and their implications on the support of and . We will only briefly discuss the next two theorems to provide a basis for analyzing vanishing gradient, look at [Arjovsky and Bottou, 2017] for the proofs.
Theorem 2 Let 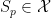 and
and 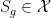 be the supports of and respectively. Assume
be the supports of and respectively. Assume  and
and  are disjoint compact sets, then there exists a smooth continuous function
are disjoint compact sets, then there exists a smooth continuous function ![{D^*: {\cal X} \rightarrow [0,1]}](https://s0.wp.com/latex.php?latex=%7BD%5E%2A%3A+%7B%5Ccal+X%7D+%5Crightarrow+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) such that:
such that:
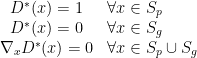
The next theorem extends Theorem 2 to the case where the supports are manifolds rather than sets.
Theorem 3 Let and be the supports of and respectively. Assume and are manifolds that are not full dimension and not perfectly aligned, then there exists a smooth continuous function such that:
To see what Theorem 3 means assume is the 2D plane. Then if real data and fake data come from two closed 1D shapes that only intersect in a finite number of points (e.g. two unit circles centered at (0.5, 0) and (-0.5, 0)) then Theorem 3 tells us that there exists a binary classifier that can perfectly separate them and be completely flat over each manifold. The assumptions are often valid in the real world tasks, specifically when considering the manifold of real images and the manifold of generated images by 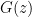 if
if 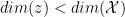 .
.
Now we are ready to investigate the problem of vanishing gradient. The optimization in Equation (2) suggests we should train till convergence and then take a step towards training , and repeat this process. However the following theorem by [Arjovsky and Bottou, 2017] shows that training till convergence results in loss of the gradient signal for updating and therefore hinders the optimization task.
Theorem 4 Given assumptions of Theorem 3 or 2, and assuming  and
and 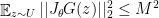 , then:
, then:
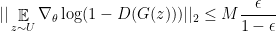
where 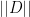 is defined as follows:
is defined as follows:
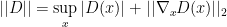
Before we prove this theorem let’s look at an immediate corollary of this theorem:
Corollary 5 Given assumptions of Theorem 4:

Therefore this corollary shows that if we find the optimal and replace it in , the gradient wrt would be zero, hence the term Vanishing Gradient. Now let’s look at the proof for Theorem 4.
Proof: We start by the squared of the left hand side. Since norm 2 is a convex function, we can use Jensen’s inequality to bring the expectation out of the norm, and then apply chain rule:

where 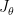 is the Jacobian wrt . Now note that
is the Jacobian wrt . Now note that  is projecting the gradient vector
is projecting the gradient vector 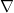 using matrix
using matrix  , and by definition the maximum factor by which a projection can increase the norm of a vector is the largest singular value of the projection matrix, known as the spectral norm of a matrix denoted by
, and by definition the maximum factor by which a projection can increase the norm of a vector is the largest singular value of the projection matrix, known as the spectral norm of a matrix denoted by 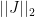 . Therefore we have:
. Therefore we have:
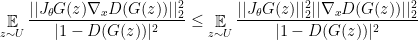
Using the definition of on the assumption we can write:

Therefore for all 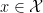 we have
we have  and
and 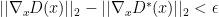 . Using these inequalities we have:
. Using these inequalities we have:

Now note that by Theorem 3 or 2, we know that  and
and 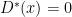 for all
for all  , thus:
, thus:

Taking a square root finishes the proof.
2.3. Modified GAN and Mode Collapse
In order to avoid the vanishing gradient issue, [Goodfellow et al. 2014] suggests a modified update rule for the generator as follows:

However the following theorem by [Arjovsky and Bottou, 2017] reveals an important flaw in this modified formulation:
Theorem 6 Let  be the optimal discriminator at
be the optimal discriminator at 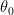 . Then:
. Then:
![\displaystyle \mathop{\mathbb E}_{z\sim U} -\nabla_{\theta} log D^*(G(z)) |_{\theta={\theta}_0} = \nabla_{\theta}[ KL(g||p) - 2JSD(p || g)]|_{\theta={\theta}_0}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+E%7D_%7Bz%5Csim+U%7D+-%5Cnabla_%7B%5Ctheta%7D+log+D%5E%2A%28G%28z%29%29+%7C_%7B%5Ctheta%3D%7B%5Ctheta%7D_0%7D+%3D+%5Cnabla_%7B%5Ctheta%7D%5B+KL%28g%7C%7Cp%29+-+2JSD%28p+%7C%7C+g%29%5D%7C_%7B%5Ctheta%3D%7B%5Ctheta%7D_0%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Before we provide the proof, let’s analyze what this theorem means. It shows that minimizing the modified objective results in minimizing KL(g||p) and maximizing JSD(p||g). The latter tries to push the distributions apart. On the other hand KL greatly penalizes high probability regions in g that have low probability in p, however does not penalizes the reverse as much. That means KL(g||p) does not penalizes much collapsing the density of g on a single mode of p. Therefore the optimum of maximizing reverse KL and JSD between two distribution happens exactly when g collapses all its density on a single mode of p, resulting in high JSD and low KL. Next we’ll prove Theorem 6.
Proof: We start by writing the definition of KL(g||p) as follows:
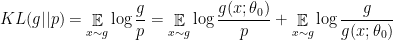
Now replacing the definition of we get:

Next we take a gradient wrt at . Note that the gradient of  is zero at since the distributions are the same. Therefore we have:
is zero at since the distributions are the same. Therefore we have:

Finally note that from Theorem 1 we have:

Calculating  completes the proof.
completes the proof.
2.4. A Simple Solution
To solve the problem of Vanishing Gradient, we can simply add noise to both the output of generator and the real data. Doing so will increase the overlap between and . Therefore it violates the assumptions of Theorem 3 and 2 and thus no longer necessarily faces Vanishing Gradient. See [Arjovsky and Bottou, 2017] for details of this noisy version of GAN and some nice properties.
2.5. A Grain of Salt
An important point to note is that the results of Theorems 1 and 6 are based on assuming the behavior of optimal discriminator. However, when optimizing , the loss does not necessarily becomes a better estimate of the divergence, the divergence only occurs at optimal . This means that minimizing generator loss does not necessarily minimize the divergence at each step. See [Fedus et al. 2017] for more details on this point.
3. State of the Art
In this section we briefly introduce Wasserstein GAN formulation and mention some very recent works focused on the problem of Mode Collapse.
3.1. Wasserstein GAN
Wasserstein GAN [Arjovsky et al. 2017] uses the following formulation:


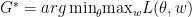
Where is a 1-Lipschitz function. Notice that the main difference is using a real valued , called the “critic” instead of discriminator, and removing the log in . Here 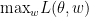 is actually approximating the dual of wasserstein distance between and , and then the generator tries to minimize this distance. The advantage is that wasserstein distance is sensitive to sample locations and not just their density, but more importantly here optimizing explicitly improves the estimate of wasserstein distance, whereas in regular GAN optimizing discriminator does not improve the estimate to JSD explicitly.
is actually approximating the dual of wasserstein distance between and , and then the generator tries to minimize this distance. The advantage is that wasserstein distance is sensitive to sample locations and not just their density, but more importantly here optimizing explicitly improves the estimate of wasserstein distance, whereas in regular GAN optimizing discriminator does not improve the estimate to JSD explicitly.
3.2. More recent works
Unrolled GAN [Metz et al. 2016], VEE-GAN [Srivastava et al. 2017] and Bi-GAN [Donahue et al. 2016] are recent approaches also addressing the problem of mode collapse.
References
Goodfellow, Ian, et al. “Generative adversarial nets.” Advances in neural information processing systems. 2014.
Arjovsky, Martin, and Léon Bottou. “Towards principled methods for training generative adversarial networks.” arXiv preprint arXiv:1701.04862 (2017).
Fedus, William, et al. “Many Paths to Equilibrium: GANs Do Not Need to Decrease aDivergence At Every Step.” arXiv preprint arXiv:1710.08446 (2017).
Metz, Luke, et al. “Unrolled generative adversarial networks.” arXiv preprint arXiv:1611.02163 (2016).
Srivastava, Akash, et al. “VEEGAN: Reducing Mode Collapse in GANs using Implicit Variational Learning.” arXiv preprint arXiv:1705.07761 (2017).
Donahue, Jeff, Philipp Krähenbühl, and Trevor Darrell. “Adversarial feature learning.” arXiv preprint arXiv:1605.09782 (2016).
Arjovsky, Martin, Soumith Chintala, and Léon Bottou. “Wasserstein gan.” arXiv preprint arXiv:1701.07875 (2017).
