Arjovsky et al. [1] proposed a new framework to suppress the gradient vanishing issue in the traditional Generative Adversarial Networks (GAN) [2]. A distance measure, Earth-Mover (EM) or Wasserstein distance, is utilized to guarantee continuous and differentiable gradient of objective function during training. This blog is organized as follows. Section 1 introduces the background knowledge for unknown distribution learning. Section 2 presents the Wasserstein distance, and shows its advantages by comparing with other three different distance measures. In section 3, the framework of Wasserstein GAN is described. Finally, the discussion is given.
1. Background
Learning unknown distributions (for example, for the learning of generative models) is fundamental problem in machine learning. Data is sampled from unknown distribution  , the goal is to learn a distribution
, the goal is to learn a distribution 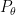 to approximate the real one ,
to approximate the real one ,  are the parameters of the distribution. Usually, there have two approaches to achieve this goal. The first one is to directly learn the probability density function , e.g. using maximum likelihood estimation (MLE). Yet may be difficult to obtain, and another approach is to learn a function that transforms an existing distribution
are the parameters of the distribution. Usually, there have two approaches to achieve this goal. The first one is to directly learn the probability density function , e.g. using maximum likelihood estimation (MLE). Yet may be difficult to obtain, and another approach is to learn a function that transforms an existing distribution  into . Here,
into . Here,  is some differentiable function, is a common distribution (usually uniform or Gaussian), and
is some differentiable function, is a common distribution (usually uniform or Gaussian), and 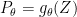 .
.
1.1. Maximum likelihood estimation
For  samples and given distribution
samples and given distribution 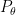 , the MLE is written as:
, the MLE is written as:

When  , the samples can approximate the real data distribution very closely. Thus, based on Eq. 1, we can get the following result:
, the samples can approximate the real data distribution very closely. Thus, based on Eq. 1, we can get the following result:

In the last line of Eq. 2, the new term  is the entropy of . Here this entropy value is a constant, and it will not impact the searching of
is the entropy of . Here this entropy value is a constant, and it will not impact the searching of  for minimizing Eq. 2. According the definition of Kullback-Leibler (KL) divergence, for two continuous distributions
for minimizing Eq. 2. According the definition of Kullback-Leibler (KL) divergence, for two continuous distributions  and
and  , the KL divergence is
, the KL divergence is 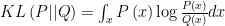 . So, Eq. 2 can be further written as:
. So, Eq. 2 can be further written as:
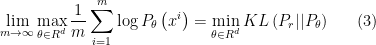
However, for a sample  , if
, if  while
while  , the KL divergence will be close to
, the KL divergence will be close to 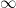 . This is bad for the MLE learning because will be very likely to have value zeros. A typical method to fix the issue is to add random noise to the learning of distribution. This ensures the distribution is defined everywhere. But this way may increase computation and the noise models may still require handcrafted selection and design.
. This is bad for the MLE learning because will be very likely to have value zeros. A typical method to fix the issue is to add random noise to the learning of distribution. This ensures the distribution is defined everywhere. But this way may increase computation and the noise models may still require handcrafted selection and design.
1.2. Generative adversarial networks
Generative Adversarial Networks is a well known example of the indirectly approach (i.e. the distribution transformation discussed above) for distribution learning. The training of GAN is a competing game that includes two neural networks. The input data for the first network, generator, is some noise data (e.g. noise image), and it tries to generate some “intermediate” samples for the other network. The second network, discriminator (or called critic), receives either a generated sample or a real data sample, and tries to learn a model that can distinguish between the “fake” and real data. The generator is trained to fool the discriminator who utilizes the real data. After lots of iterative training, the generator would have the ability to obtain the results that are very close to the real ones.
Formally, the competition between the generator  and the discriminator
and the discriminator  is the minimax objective:
is the minimax objective:

![\displaystyle V\left( {D,G} \right) = \mathop E\limits_{x \sim {P_r}} \left[ {\log \left( {D\left( x \right)} \right)} \right] + \mathop E\limits_{x \sim {P_g}} \left[ {\log \left( {1 - D\left( {x} \right)} \right)} \right] \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++V%5Cleft%28+%7BD%2CG%7D+%5Cright%29+%3D+%5Cmathop+E%5Climits_%7Bx+%5Csim+%7BP_r%7D%7D+%5Cleft%5B+%7B%5Clog+%5Cleft%28+%7BD%5Cleft%28+x+%5Cright%29%7D+%5Cright%29%7D+%5Cright%5D+%2B+%5Cmathop+E%5Climits_%7Bx+%5Csim+%7BP_g%7D%7D+%5Cleft%5B+%7B%5Clog+%5Cleft%28+%7B1+-+D%5Cleft%28+%7Bx%7D+%5Cright%29%7D+%5Cright%29%7D+%5Cright%5D+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
where  is the model distribution implicitly defined by
is the model distribution implicitly defined by 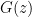 ,
, 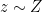 (the input
(the input  to the generator is sampled from some simple noise distribution , such as the uniform distribution or a spherical Gaussian distribution).
to the generator is sampled from some simple noise distribution , such as the uniform distribution or a spherical Gaussian distribution).
The first step to solve the objective function of GAN is to find the optimal discriminator. Set the derivative of  (with respect to ) as 0, and the optimal
(with respect to ) as 0, and the optimal  is got by the follows:
is got by the follows:

Put the optimal back into , and we can set the following equations:
![\displaystyle V\left( {{D^*},G} \right) = \mathop E\limits_{x \sim {P_r}} \left[ {\log \frac{{{P_r}\left( x \right)}}{{\frac{1}{2}\left( {{P_r}\left( x \right) + {P_g}\left( x \right)} \right)}}} \right] - \log 2 + \mathop E\limits_{x \sim {P_g}} \left[ {\log \frac{{{P_g}\left( x \right)}}{{\frac{1}{2}\left( {{P_r}\left( x \right) + {P_g}\left( x \right)} \right)}}} \right] - \log 2 \Rightarrow](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++V%5Cleft%28+%7B%7BD%5E%2A%7D%2CG%7D+%5Cright%29+%3D+%5Cmathop+E%5Climits_%7Bx+%5Csim+%7BP_r%7D%7D+%5Cleft%5B+%7B%5Clog+%5Cfrac%7B%7B%7BP_r%7D%5Cleft%28+x+%5Cright%29%7D%7D%7B%7B%5Cfrac%7B1%7D%7B2%7D%5Cleft%28+%7B%7BP_r%7D%5Cleft%28+x+%5Cright%29+%2B+%7BP_g%7D%5Cleft%28+x+%5Cright%29%7D+%5Cright%29%7D%7D%7D+%5Cright%5D+-+%5Clog+2+%2B+%5Cmathop+E%5Climits_%7Bx+%5Csim+%7BP_g%7D%7D+%5Cleft%5B+%7B%5Clog+%5Cfrac%7B%7B%7BP_g%7D%5Cleft%28+x+%5Cright%29%7D%7D%7B%7B%5Cfrac%7B1%7D%7B2%7D%5Cleft%28+%7B%7BP_r%7D%5Cleft%28+x+%5Cright%29+%2B+%7BP_g%7D%5Cleft%28+x+%5Cright%29%7D+%5Cright%29%7D%7D%7D+%5Cright%5D+-+%5Clog+2+%5CRightarrow+&bg=ffffff&fg=000000&s=0&c=20201002)
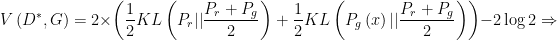

where the  represents the Jensen-Shannon (JS) divergence, defined as:
represents the Jensen-Shannon (JS) divergence, defined as: 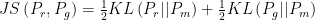 , and
, and  is the mixture
is the mixture  .
.
Thus, minimizing Eq. 7 with respect to is equal to minimize the JS divergence when we have . In the almost situations of training, and (almost) have no overlap, then 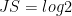 , the gradient will vanish.
, the gradient will vanish.
2. Distance Measures
2.1. Definition of Wasserstein distance
Because the KL and JS divergences exist the gradient vanishing issue, the Earth-Mover (EM) distance or Wasserstein distance is utilized as measure for GAN framework training. Here, the definition of Wasserstein distance is shown as follows:
![\displaystyle W\left( {{P_r},{P_g}} \right) = \mathop {\inf }\limits_{\gamma \in \prod \left( {{P_r},{P_g}} \right)} {E_{\left( {x,y} \right) \sim \gamma }}\left[ {\left\| {x - y} \right\|} \right] \ \ \ \ \ (8)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++W%5Cleft%28+%7B%7BP_r%7D%2C%7BP_g%7D%7D+%5Cright%29+%3D+%5Cmathop+%7B%5Cinf+%7D%5Climits_%7B%5Cgamma+%5Cin+%5Cprod+%5Cleft%28+%7B%7BP_r%7D%2C%7BP_g%7D%7D+%5Cright%29%7D+%7BE_%7B%5Cleft%28+%7Bx%2Cy%7D+%5Cright%29+%5Csim+%5Cgamma+%7D%7D%5Cleft%5B+%7B%5Cleft%5C%7C+%7Bx+-+y%7D+%5Cright%5C%7C%7D+%5Cright%5D+%5C+%5C+%5C+%5C+%5C+%288%29&bg=ffffff&fg=000000&s=0&c=20201002)
Here, 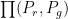 denotes the set of all joint distributions
denotes the set of all joint distributions 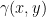 whose marginal distributions are and .
whose marginal distributions are and . 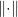 could be the
could be the  norm.
norm. ![{{E_{\left( {x,y} \right) \sim \gamma }}\left[ {\left\| {x - y} \right\|} \right] = \int_x {\int_y {\gamma \left( {x,y} \right)\left\| {x - y} \right\|dxdy} }}](https://s0.wp.com/latex.php?latex=%7B%7BE_%7B%5Cleft%28+%7Bx%2Cy%7D+%5Cright%29+%5Csim+%5Cgamma+%7D%7D%5Cleft%5B+%7B%5Cleft%5C%7C+%7Bx+-+y%7D+%5Cright%5C%7C%7D+%5Cright%5D+%3D+%5Cint_x+%7B%5Cint_y+%7B%5Cgamma+%5Cleft%28+%7Bx%2Cy%7D+%5Cright%29%5Cleft%5C%7C+%7Bx+-+y%7D+%5Cright%5C%7Cdxdy%7D+%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , so the Wasserstein distance assesses how much effort is cost to move a point with one distribution to another point with different distribution, and
, so the Wasserstein distance assesses how much effort is cost to move a point with one distribution to another point with different distribution, and  represents the moved distance.
represents the moved distance.
Consider a simple example, let it exist in probability distributions defined over 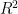 . The true data distribution is
. The true data distribution is 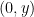 . The distributions is set as
. The distributions is set as  . is the parameter, and
. is the parameter, and  of the two distributions is sampled from
of the two distributions is sampled from ![{U[0,1]}](https://s0.wp.com/latex.php?latex=%7BU%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . For comparisons, KL divergence, JS divergence and Total variation distance (
. For comparisons, KL divergence, JS divergence and Total variation distance ( ) are employed. The follows show the different performance of the four distance measures.
) are employed. The follows show the different performance of the four distance measures.
Total Variation (TV) distance:

Kullback-Leibler (KL) divergence:

Jensen-Shannon (JS) divergence:

Wasserstein distance:

Here, the output of Wasserstein distance depends on the parameter . While for the other three measures, when and have no overlap (very common situation in the GAN training), their outputs are binary, and may cause no meaningful gradient.
This example shows that when using TV, KL or JS as distance measure for distribution estimation, there exist situations that do not make the learning converge. Moreover, these may also cause the gradient to be zero while computing 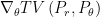 ,
,  or
or 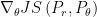 . But the Wasserstein distance could suppress the non-convergence and gradient vanishing issues.
. But the Wasserstein distance could suppress the non-convergence and gradient vanishing issues.
2.2. Theorem proof
Now, let us go deeper to see for general conditions, the Wasserstein distance  is also continuous and differentiable, and even when the transform function is neural network, will also work well.
is also continuous and differentiable, and even when the transform function is neural network, will also work well.
Theorem 1: Let be a fixed distribution over 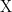 . Let be a random variable (e.g Gaussian) over
. Let be a random variable (e.g Gaussian) over 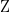 . Let
. Let  :
:  be a function, that will be denoted
be a function, that will be denoted  with the first coordinate and the second. Let denote the distribution of . Then,
with the first coordinate and the second. Let denote the distribution of . Then,
1. If is continuous in , so is .
2. If is locally Lipschitz and satisfies regularity assumption  , then is continuous everywhere, and differentiable almost everywhere.
, then is continuous everywhere, and differentiable almost everywhere.
3. Statements – are false for
are false for 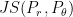 and all the
and all the 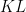 .
.
Assumption 1: Let :  be locally Lipschitz. For a distribution
be locally Lipschitz. For a distribution  over , if satisfies this assumption, then exists local Lipschitz constants
over , if satisfies this assumption, then exists local Lipschitz constants  such that:
such that:
![\displaystyle {E_{z \sim p}}\left[ {L\left( {\theta ,z} \right)} \right] < + \infty](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7BE_%7Bz+%5Csim+p%7D%7D%5Cleft%5B+%7BL%5Cleft%28+%7B%5Ctheta+%2Cz%7D+%5Cright%29%7D+%5Cright%5D+%3C+%2B+%5Cinfty+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof of Theorem 1: 1. Bound  , where and
, where and  are two parameter vectors in
are two parameter vectors in 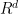 . The distribution of the joint
. The distribution of the joint 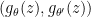 is
is  , and has
, and has  . Based on the definition of the Wasserstein distance in Eq. 8, we have:
. Based on the definition of the Wasserstein distance in Eq. 8, we have:
![\displaystyle W\left( {{P_\theta },{P_{\theta '}}} \right) \le \int_{\rm X \times \rm X} {\left\| {x - y} \right\|d\gamma } = {E_{\left( {x,y} \right) \sim \gamma }}\left[ {\left\| {x - y} \right\|} \right] = {E_z}\left[ {\left\| {{g_\theta }\left( z \right) - {g_{\theta '}}\left( z \right)} \right\|} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++W%5Cleft%28+%7B%7BP_%5Ctheta+%7D%2C%7BP_%7B%5Ctheta+%27%7D%7D%7D+%5Cright%29+%5Cle+%5Cint_%7B%5Crm+X+%5Ctimes+%5Crm+X%7D+%7B%5Cleft%5C%7C+%7Bx+-+y%7D+%5Cright%5C%7Cd%5Cgamma+%7D+%3D+%7BE_%7B%5Cleft%28+%7Bx%2Cy%7D+%5Cright%29+%5Csim+%5Cgamma+%7D%7D%5Cleft%5B+%7B%5Cleft%5C%7C+%7Bx+-+y%7D+%5Cright%5C%7C%7D+%5Cright%5D+%3D+%7BE_z%7D%5Cleft%5B+%7B%5Cleft%5C%7C+%7B%7Bg_%5Ctheta+%7D%5Cleft%28+z+%5Cright%29+-+%7Bg_%7B%5Ctheta+%27%7D%7D%5Cleft%28+z+%5Cright%29%7D+%5Cright%5C%7C%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
is continuous in , and is compact. So for all and , as 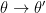 , and we have:
, and we have:
![\displaystyle W\left( {{P_\theta },{P_{\theta '}}} \right) \le {E_z}\left[ {\left\| {{g_\theta }\left( z \right) - {g_{\theta '}}\left( z \right)} \right\|} \right]{ \rightarrow _{\theta \rightarrow \theta '}}0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++W%5Cleft%28+%7B%7BP_%5Ctheta+%7D%2C%7BP_%7B%5Ctheta+%27%7D%7D%7D+%5Cright%29+%5Cle+%7BE_z%7D%5Cleft%5B+%7B%5Cleft%5C%7C+%7B%7Bg_%5Ctheta+%7D%5Cleft%28+z+%5Cright%29+-+%7Bg_%7B%5Ctheta+%27%7D%7D%5Cleft%28+z+%5Cright%29%7D+%5Cright%5C%7C%7D+%5Cright%5D%7B+%5Crightarrow+_%7B%5Ctheta+%5Crightarrow+%5Ctheta+%27%7D%7D0+&bg=ffffff&fg=000000&s=0&c=20201002)
Moreover, because 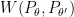 is a distance measure, then using the triangle inequality for
is a distance measure, then using the triangle inequality for  and
and  , we have:
, we have:
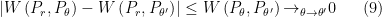
Thus, as is very close to  ,
,  is also very close to zero, so is continuous when is continuous in . So the item of Theorem is proved.
is also very close to zero, so is continuous when is continuous in . So the item of Theorem is proved.
2. If is locally Lipschitz, for a given pair  , there exist a constant and an open set
, there exist a constant and an open set  . For every
. For every 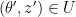 , we have:
, we have:
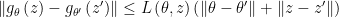
If set  and compute expectation, then we have:
and compute expectation, then we have:
![\displaystyle {E_z}\left[ {\left\| {{g_\theta }\left( z \right) - {g_{\theta '}}\left( z \right)} \right\|} \right] \le \left\| {\theta - \theta '} \right\|{E_z}\left[ {L\left( {\theta ,z} \right)} \right] \ \ \ \ \ (10)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7BE_z%7D%5Cleft%5B+%7B%5Cleft%5C%7C+%7B%7Bg_%5Ctheta+%7D%5Cleft%28+z+%5Cright%29+-+%7Bg_%7B%5Ctheta+%27%7D%7D%5Cleft%28+z+%5Cright%29%7D+%5Cright%5C%7C%7D+%5Cright%5D+%5Cle+%5Cleft%5C%7C+%7B%5Ctheta+-+%5Ctheta+%27%7D+%5Cright%5C%7C%7BE_z%7D%5Cleft%5B+%7BL%5Cleft%28+%7B%5Ctheta+%2Cz%7D+%5Cright%29%7D+%5Cright%5D+%5C+%5C+%5C+%5C+%5C+%2810%29&bg=ffffff&fg=000000&s=0&c=20201002)
Define ![{L\left( \theta \right) = {E_z}\left[ {L\left( {\theta ,z} \right)} \right]}](https://s0.wp.com/latex.php?latex=%7BL%5Cleft%28+%5Ctheta+%5Cright%29+%3D+%7BE_z%7D%5Cleft%5B+%7BL%5Cleft%28+%7B%5Ctheta+%2Cz%7D+%5Cright%29%7D+%5Cright%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , and using Eq. 9 and Eq. 10, we have:
, and using Eq. 9 and Eq. 10, we have:
![\displaystyle \left| {W\left( {{P_r},{P_\theta }} \right) - W\left( {{P_r},{P_{\theta '}}} \right)} \right| \le W\left( {{P_\theta },{P_{\theta '}}} \right) \le {E_z}\left[ {\left\| {{g_\theta }\left( z \right) - {g_{\theta '}}\left( z \right)} \right\|} \right] \le L\left( \theta \right)\left\| {\theta - \theta '} \right\| \ \ \ \ \ (11)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cleft%7C+%7BW%5Cleft%28+%7B%7BP_r%7D%2C%7BP_%5Ctheta+%7D%7D+%5Cright%29+-+W%5Cleft%28+%7B%7BP_r%7D%2C%7BP_%7B%5Ctheta+%27%7D%7D%7D+%5Cright%29%7D+%5Cright%7C+%5Cle+W%5Cleft%28+%7B%7BP_%5Ctheta+%7D%2C%7BP_%7B%5Ctheta+%27%7D%7D%7D+%5Cright%29+%5Cle+%7BE_z%7D%5Cleft%5B+%7B%5Cleft%5C%7C+%7B%7Bg_%5Ctheta+%7D%5Cleft%28+z+%5Cright%29+-+%7Bg_%7B%5Ctheta+%27%7D%7D%5Cleft%28+z+%5Cright%29%7D+%5Cright%5C%7C%7D+%5Cright%5D+%5Cle+L%5Cleft%28+%5Ctheta+%5Cright%29%5Cleft%5C%7C+%7B%5Ctheta+-+%5Ctheta+%27%7D+%5Cright%5C%7C+%5C+%5C+%5C+%5C+%5C+%2811%29&bg=ffffff&fg=000000&s=0&c=20201002)
This shows that  is locally Lipschitz, and is differentiable everywhere. So, the item of Theorem is proved.
is locally Lipschitz, and is differentiable everywhere. So, the item of Theorem is proved.
3. The example in Section 2 has shown a counterexample for item 3.
Corollary 1: Let be any feedforward neural network parameterized by , 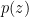 is a prior over , and
is a prior over , and ![{{E_{z \sim {P_r}}}\left[ {\left\| z \right\|} \right] < \infty}](https://s0.wp.com/latex.php?latex=%7B%7BE_%7Bz+%5Csim+%7BP_r%7D%7D%7D%5Cleft%5B+%7B%5Cleft%5C%7C+z+%5Cright%5C%7C%7D+%5Cright%5D+%3C+%5Cinfty%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Then assumption is satisfied and therefore is continuous everywhere and differentiable almost everywhere.
. Then assumption is satisfied and therefore is continuous everywhere and differentiable almost everywhere.
Proof of Corollary 1: If there exists ![{{E_{z \sim p\left( z \right)}}\left[ {\left\| {{\nabla _{\theta ,z}}{g_\theta }\left( z \right)} \right\|} \right] < + \infty}](https://s0.wp.com/latex.php?latex=%7B%7BE_%7Bz+%5Csim+p%5Cleft%28+z+%5Cright%29%7D%7D%5Cleft%5B+%7B%5Cleft%5C%7C+%7B%7B%5Cnabla+_%7B%5Ctheta+%2Cz%7D%7D%7Bg_%5Ctheta+%7D%5Cleft%28+z+%5Cright%29%7D+%5Cright%5C%7C%7D+%5Cright%5D+%3C+%2B+%5Cinfty%7D&bg=ffffff&fg=000000&s=0&c=20201002) , then we can prove the corollary .
, then we can prove the corollary .
Let  is the number of layers, and
is the number of layers, and 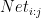 is the application of layers
is the application of layers  to
to  inclusively (e.g.
inclusively (e.g.  ), then we have:
), then we have:


where 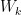 are the weight matrices, and
are the weight matrices, and 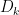 are the diagonal Jacobians of the nonlinearities.
are the diagonal Jacobians of the nonlinearities.
Let  be the Lipschitz constant of the nonlinearity of the network, and then get
be the Lipschitz constant of the nonlinearity of the network, and then get  and
and  . Consider the definition of gradient in multivariable function, and then we have:
. Consider the definition of gradient in multivariable function, and then we have:

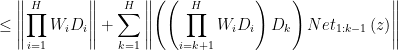

If set  and
and  , so we get the following formula, and prove Corollary 1.
, so we get the following formula, and prove Corollary 1.
![\displaystyle {E_{z \sim p\left( z \right)}}\left[ {\left\| {{\nabla _{\theta ,z}}{g_\theta }\left( z \right)} \right\|} \right] \le {C_1}\left( \theta \right) + {C_2}\left( \theta \right){E_{z \sim p\left( z \right)}}\left[ {\left\| z \right\|} \right] < + \infty \ \ \ \ \ (12)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7BE_%7Bz+%5Csim+p%5Cleft%28+z+%5Cright%29%7D%7D%5Cleft%5B+%7B%5Cleft%5C%7C+%7B%7B%5Cnabla+_%7B%5Ctheta+%2Cz%7D%7D%7Bg_%5Ctheta+%7D%5Cleft%28+z+%5Cright%29%7D+%5Cright%5C%7C%7D+%5Cright%5D+%5Cle+%7BC_1%7D%5Cleft%28+%5Ctheta+%5Cright%29+%2B+%7BC_2%7D%5Cleft%28+%5Ctheta+%5Cright%29%7BE_%7Bz+%5Csim+p%5Cleft%28+z+%5Cright%29%7D%7D%5Cleft%5B+%7B%5Cleft%5C%7C+z+%5Cright%5C%7C%7D+%5Cright%5D+%3C+%2B+%5Cinfty+%5C+%5C+%5C+%5C+%5C+%2812%29&bg=ffffff&fg=000000&s=0&c=20201002)
3. Wasserstein GAN
Although the Wasserstein distance shows good properties for distribution learning, but the original formula of is intractable. So the Kantorovich-Rubenstein (KR) duality is utilized to approximate .
![\displaystyle W\left( {{P_r},{P_\theta }} \right) = \mathop {\sup }\limits_{\tilde f \in F} \left( {{E_{x \sim {P_r}}}\left[ {\tilde f\left( x \right)} \right] - {E_{z \sim p\left( z \right)}}\left[ {\tilde f\left( {{g_\theta }\left( z \right)} \right)} \right]} \right),{\left\| {\tilde f} \right\|_L} \le 1](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++W%5Cleft%28+%7B%7BP_r%7D%2C%7BP_%5Ctheta+%7D%7D+%5Cright%29+%3D+%5Cmathop+%7B%5Csup+%7D%5Climits_%7B%5Ctilde+f+%5Cin+F%7D+%5Cleft%28+%7B%7BE_%7Bx+%5Csim+%7BP_r%7D%7D%7D%5Cleft%5B+%7B%5Ctilde+f%5Cleft%28+x+%5Cright%29%7D+%5Cright%5D+-+%7BE_%7Bz+%5Csim+p%5Cleft%28+z+%5Cright%29%7D%7D%5Cleft%5B+%7B%5Ctilde+f%5Cleft%28+%7B%7Bg_%5Ctheta+%7D%5Cleft%28+z+%5Cright%29%7D+%5Cright%29%7D+%5Cright%5D%7D+%5Cright%29%2C%7B%5Cleft%5C%7C+%7B%5Ctilde+f%7D+%5Cright%5C%7C_L%7D+%5Cle+1+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \Rightarrow {E_{x \sim {P_r}}}\left[ {f\left( x \right)} \right] - {E_{z \sim p\left( z \right)}}\left[ {f\left( {{g_\theta }\left( z \right)} \right)} \right],f \in F \ \ \ \ \ (13)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5CRightarrow+%7BE_%7Bx+%5Csim+%7BP_r%7D%7D%7D%5Cleft%5B+%7Bf%5Cleft%28+x+%5Cright%29%7D+%5Cright%5D+-+%7BE_%7Bz+%5Csim+p%5Cleft%28+z+%5Cright%29%7D%7D%5Cleft%5B+%7Bf%5Cleft%28+%7B%7Bg_%5Ctheta+%7D%5Cleft%28+z+%5Cright%29%7D+%5Cright%29%7D+%5Cright%5D%2Cf+%5Cin+F+%5C+%5C+%5C+%5C+%5C+%2813%29&bg=ffffff&fg=000000&s=0&c=20201002)
where the supremum is over all the 1-Lipschitz functions,  ,
, 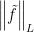 is the Lipschitz constant of
is the Lipschitz constant of 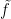 .
.  is the function that satisfies the supremum operation.
is the function that satisfies the supremum operation.
Thus, based on , the envelope theorem can be applied to the following equation:
![\displaystyle {\nabla _\theta }W\left( {{P_r},{P_\theta }} \right) = {\nabla _\theta }\left( {{E_{x \sim {P_r}}}\left[ {f\left( x \right)} \right] - {E_{z \sim p\left( z \right)}}\left[ {f\left( {{g_\theta }\left( z \right)} \right)} \right]} \right) = - {E_{z \sim p\left( z \right)}}\left[ {{\nabla _\theta }f\left( {{g_\theta }\left( z \right)} \right)} \right] \ \ \ \ \ (14)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cnabla+_%5Ctheta+%7DW%5Cleft%28+%7B%7BP_r%7D%2C%7BP_%5Ctheta+%7D%7D+%5Cright%29+%3D+%7B%5Cnabla+_%5Ctheta+%7D%5Cleft%28+%7B%7BE_%7Bx+%5Csim+%7BP_r%7D%7D%7D%5Cleft%5B+%7Bf%5Cleft%28+x+%5Cright%29%7D+%5Cright%5D+-+%7BE_%7Bz+%5Csim+p%5Cleft%28+z+%5Cright%29%7D%7D%5Cleft%5B+%7Bf%5Cleft%28+%7B%7Bg_%5Ctheta+%7D%5Cleft%28+z+%5Cright%29%7D+%5Cright%29%7D+%5Cright%5D%7D+%5Cright%29+%3D+-+%7BE_%7Bz+%5Csim+p%5Cleft%28+z+%5Cright%29%7D%7D%5Cleft%5B+%7B%7B%5Cnabla+_%5Ctheta+%7Df%5Cleft%28+%7B%7Bg_%5Ctheta+%7D%5Cleft%28+z+%5Cright%29%7D+%5Cright%29%7D+%5Cright%5D+%5C+%5C+%5C+%5C+%5C+%2814%29&bg=ffffff&fg=000000&s=0&c=20201002)
Therefore, if we employ a parameterized family of function  (with the 1-Lipschitz constraints) for the optimization of , we can use the follows:
(with the 1-Lipschitz constraints) for the optimization of , we can use the follows:
![\displaystyle \mathop {\max }\limits_w \mathop E\limits_{x \sim {P_r}} \left[ {{f_w}\left( x \right)} \right] - \mathop E\limits_{z \sim p\left( z \right)} \left[ {{f_w}\left( {{g_\theta }\left( z \right)} \right)} \right] \ \ \ \ \ (15)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop+%7B%5Cmax+%7D%5Climits_w+%5Cmathop+E%5Climits_%7Bx+%5Csim+%7BP_r%7D%7D+%5Cleft%5B+%7B%7Bf_w%7D%5Cleft%28+x+%5Cright%29%7D+%5Cright%5D+-+%5Cmathop+E%5Climits_%7Bz+%5Csim+p%5Cleft%28+z+%5Cright%29%7D+%5Cleft%5B+%7B%7Bf_w%7D%5Cleft%28+%7B%7Bg_%5Ctheta+%7D%5Cleft%28+z+%5Cright%29%7D+%5Cright%29%7D+%5Cright%5D+%5C+%5C+%5C+%5C+%5C+%2815%29&bg=ffffff&fg=000000&s=0&c=20201002)
The KR-duality approximated Wasserstein distance can be applied for a GAN framework, whose training process includes training 3 steps:
1. For a fixed , compute the gradient of with respect to  . In order to guarantee the Lipschitz constraints, a weight clipping sub-step is implemented, making
. In order to guarantee the Lipschitz constraints, a weight clipping sub-step is implemented, making ![{w=[-c, c]}](https://s0.wp.com/latex.php?latex=%7Bw%3D%5B-c%2C+c%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) (e.g.
(e.g.  ).
).
2. When get an optimal (discriminator), compute ![{- {E_{z \sim p\left( z \right)}}\left[ {{\nabla _\theta }f\left( {{g_\theta }\left( z \right)} \right)} \right]}](https://s0.wp.com/latex.php?latex=%7B-+%7BE_%7Bz+%5Csim+p%5Cleft%28+z+%5Cright%29%7D%7D%5Cleft%5B+%7B%7B%5Cnabla+_%5Ctheta+%7Df%5Cleft%28+%7B%7Bg_%5Ctheta+%7D%5Cleft%28+z+%5Cright%29%7D+%5Cright%29%7D+%5Cright%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) for finding the optimal parameters of generator.
for finding the optimal parameters of generator.
3. Update for the next iteration.
4. Discussion
The major contribution of methodology in the Wasserstein GAN is that a KR-duality approximated Wasserstein distance is employed to build a GAN framework. The Wasserstein GAN can suppress the gradient vanishing issue in the traditional methods, and provide remarkably clean gradients. Therefore, even using the batch-normalization-removed generator from some previous approaches (e.g. DCGAN [3]), the Wasserstein GAN can also work very well, yet the previous GANs fail. However, one possible drawback of the Wasserstein GAN is that its performance highly depends on the selection of threshold  . An unsuitable may cause the 1-Lipschitz constraints unsatisfied. Therefore, a further improvement is the method: “Improved Training of Wasserstein GANs” [4]. This method introduces a gradient penalty,
. An unsuitable may cause the 1-Lipschitz constraints unsatisfied. Therefore, a further improvement is the method: “Improved Training of Wasserstein GANs” [4]. This method introduces a gradient penalty, ![{\mathop E\limits_{x \sim {P_{\hat x}}} {\left[ {{{\left\| {{\nabla _x}D\left( x \right)} \right\|}_2} - 1} \right]^2}}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop+E%5Climits_%7Bx+%5Csim+%7BP_%7B%5Chat+x%7D%7D%7D+%7B%5Cleft%5B+%7B%7B%7B%5Cleft%5C%7C+%7B%7B%5Cnabla+_x%7DD%5Cleft%28+x+%5Cright%29%7D+%5Cright%5C%7C%7D_2%7D+-+1%7D+%5Cright%5D%5E2%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , into the objective function (where
, into the objective function (where 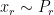 ,
, 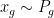 ,
,  ,
, ![{\epsilon \in [0, 1]}](https://s0.wp.com/latex.php?latex=%7B%5Cepsilon+%5Cin+%5B0%2C+1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) ). The gradient penalty plays a role to automatically regularize the objective function, and thus increase the robust of Wasserstein GAN for different applications. All in all, the Wasserstein GAN offers an very effective distance measure for the development of GAN models.
). The gradient penalty plays a role to automatically regularize the objective function, and thus increase the robust of Wasserstein GAN for different applications. All in all, the Wasserstein GAN offers an very effective distance measure for the development of GAN models.
Reference:
[1] Arjovsky, Martin, Soumith Chintala, and Léon Bottou. “Wasserstein gan.” arXiv preprint arXiv:1701.07875 (2017).
[2] Arjovsky, Martin, and Léon Bottou. “Towards principled methods for training generative adversarial networks.” arXiv preprint arXiv:1701.04862 (2017).
[3] Radford, Alec, Luke Metz, and Soumith Chintala. “Unsupervised representation learning with deep convolutional generative adversarial networks.” arXiv preprint arXiv:1511.06434 (2015).
[4] Gulrajani, Ishaan, et al. “Improved training of wasserstein gans.” arXiv preprint arXiv:1704.00028 (2017).
